Block Web Crawlers from Certain Web Pages
Do you have certain parts of a website that you don’t want indexed by a search engine? If so, you can block search web crawlers from the page or pages that you want to be web crawler free. It is much easier than you might think and it all has to do with a file called robots.txt.
 Using The Robots.txt File to Block Web Crawlers
Using The Robots.txt File to Block Web Crawlers

{kind=link}
When you don’t want your website or specific pages of your website to be crawled and subsequently indexed then you’re going to have to use something known as a robots.txt file. This particular file restricts all or most access to certain areas of your website and will always be complied to by the search engines’ web crawlers.
You can easily have a robots.txt file created through Google services and even monitor which URLs have been blocked from crawling in their Webmaster Tools section. Other search engines offer the same services and also comply with the file so your content can be private.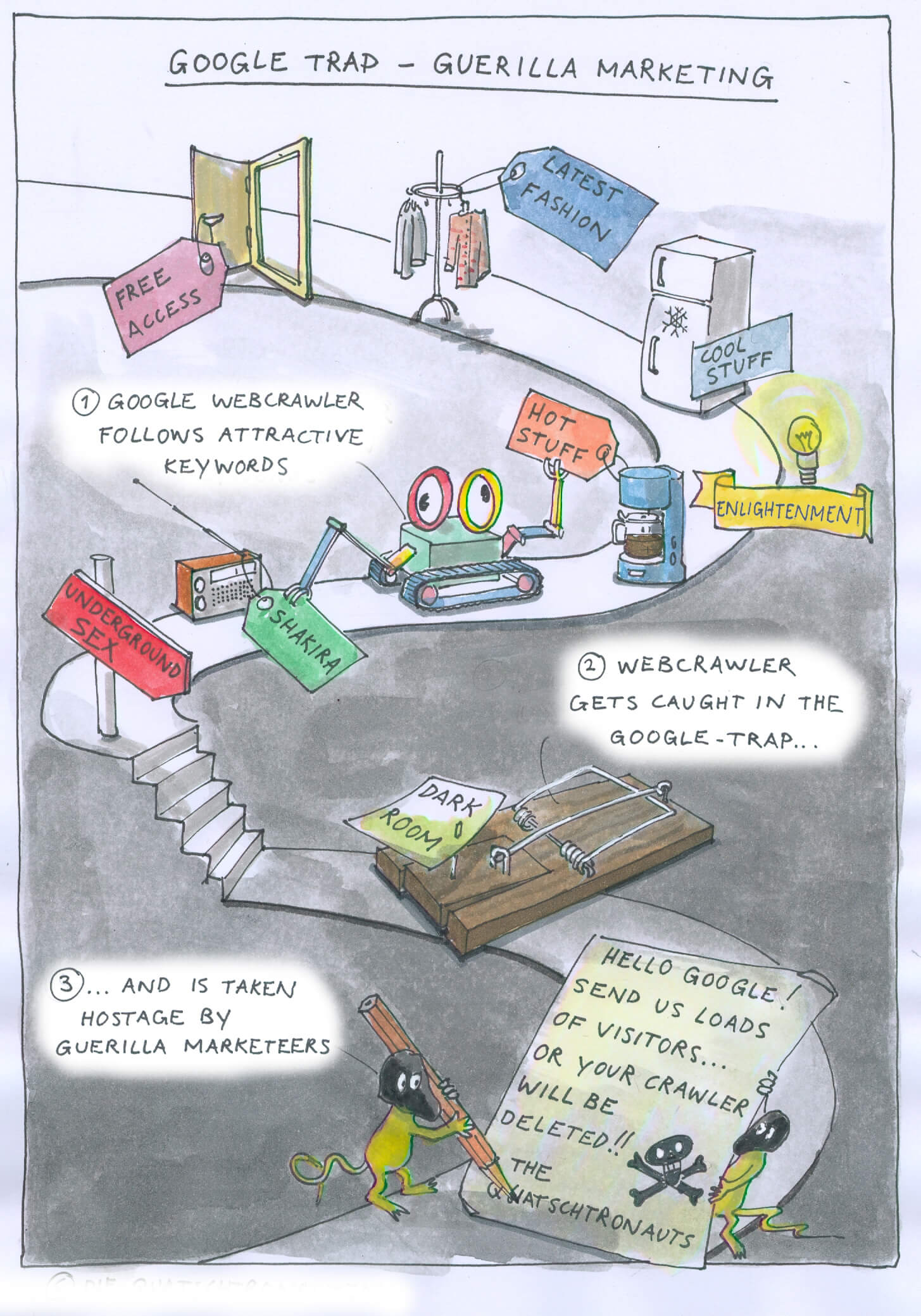
There are two ways you can block access to certain web pages: knowing the root of your domain or utilizing the robots meta tag. Here are some things to know about restricting access to web crawlers.
- If you don’t want anything on a particular page to be indexed whatsoever, the best path is to use either the noindex meta tag or x-robots-tag, especially when it comes to the Google web crawlers.
- Not all content might be safe from indexing, however. If there are links to the page on other websites, then that particular content will still be found on search engines because of the outside links.
- There are black hat search optimization tactics used by spammers that circumvent the robots.txt file. If there is very sensitive information on that web page, then the best strategy is to use the file as well as using password protection.
If you ever want to start indexing a certain web page, all you have to do is remove the file and allow the web crawlers to index it. Websites where anything can be indexed don’t even need a robots.txt file. If you want certain content to be index free, the robots.txt file is your best bet and is very easy to set up.
Cultura Web Design offers a variety of services including Internet Marketing and SEO for small businesses in Miami and Fort Lauderdale. You can learn more about our services or contact us for a personal interview.
Have a Project in Mind?
We will contact you with a customized quote for your project.
Difference Between Branded & Non-Branded Keywords in SEO Previous Article
Internet Marketing vs. Local Business Marketing